聊聊数据结构与算法:基础知识
前言
Pascal之父Nicklaus Wirth说过:“算法+数据结构=程序”,数据结构与算法的重要性不用多说,几乎每个计算机科学专业的学生或者学习编程的程序员都必须要学的一门理论课程。但是学习难度是比较高的,尤其是算法,难先不说,实际工作中也用的不多,现在写一个程序往往有许多的框架和库可以直接使用,完全不用关心算法是如何实现的,学习算法的回报和成就感都没有学习一个MVC框架来得快。
但是这并不意味着数据结构与算法没有用处,如果停留在“使用”的层面只能解决已知问题,对于未遇到过的问题就无法变通应对,同时,学习这类的计算机科学理论知识,除了可以了解到底层的运作原理以外,还可以学到很多巧妙的解题思路,这些思路无论是在系统底层还是上层,小型单体应用还是大型分布式应用,都能看得到它们的存在。
算法复杂度
算法复杂度分为时间复杂度和空间复杂度。
- 时间复杂度是指执行算法所需要的计算工作量
- 空间复杂度是指执行这个算法所需要的内存空间
算法的时间复杂度是一个函数,它定性描述了该算法的运行时间,经常用来体现算法的速度有多快。
大O表示法
我们通常用大O表示法来表示算法的时间复杂度。大O阶的推导方法如下:
- 用常数1取代运行时间中的所有加法常数。
- 在修改后的运行次数函数中,只保留最高阶项。
- 如果最高阶项存在且不是1,则去除与这个项相乘的常数。
常数阶
int sum = 0, n = 100; /* 执行一次 */
sum = (1+n)*n/2; /* 执行一次 */
printf("%d", sum); /* 执行一次 */
这段代码的运行次数函数是f(n)=3,根据大O阶的推导方法,第一步把常数项3改为1,但是之后在保留最高阶项时发现没有最高阶项,所以这段代码的时间复杂度为O(1)。
线性阶
int i;
for (i = 0; i < n; i++)
{
/* 时间复杂度为O(1)的程序步骤序列 */
}
这段代码的运行次数函数是f(n)=n,因为循环体中的代码需要执行n次,没有常数项也没有最高阶项,所以这段代码的时间复杂度为O(n)。
对数阶
int count = 1;
while (count < n)
{
count = count * 2;
/* 时间复杂度为O(1)的程序步骤序列 */
}
这段代码每次都让count乘以2,直到count大于等于n,换句话说,就是2的x次方可以大于等于n,即n=2^x,得到运行次数函数是f(n)=log2(n),由于对数的底数2对整体复杂度影响不大可以忽略,所以这段代码的时间复杂度为O(log(n))。
平方阶
int i,j;
for (i = 0; i < n; i++)
{
for (j = 0; j < n; j++)
{
/* 时间复杂度为O(1)的程序步骤序列 */
}
}
这段代码是一个循环嵌套,所以很明显这段代码的时间复杂度为O(n^2)。
再看一个稍微复杂一点的例子:
n++; /* 执行次数为1 */
function(n); /* 执行次数为n */
int i,j;
for (i = 0; i < n; i++) /* 执行次数为n^2 */
{
function(i);
}
for (i = 0; i < n; i++) /* 执行次数为n(n+1)/2 */
{
for (j = i; j < n; j++)
{
/* 时间复杂度为O(1)的程序步骤序列 */
}
}
这段代码的执行次数f(n)=1+n+n^2+(n(n+1)/2)=(3/2)n^2+(3/2)n+1,根据大O阶的推导方法,保留最高阶项得到(3/2)n^2,去除与这个项相乘的常数得到n^2,所以最终这段代码的时间复杂度是O(n^2)。
常见的时间复杂度
- 常数阶 O(1)
- 线性阶 O(n)
- 平方阶 O(n^2)
- 对数阶 O(log(n))
- nlogn阶 O(n log(n))
- 立方阶 O(n^3)
- 指数阶 O(2^n)
- 阶乘阶 O(n!)
常见的时间复杂度从小到大依次是:
O(1) < O(log(n)) < O(n) < O(n log(n)) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
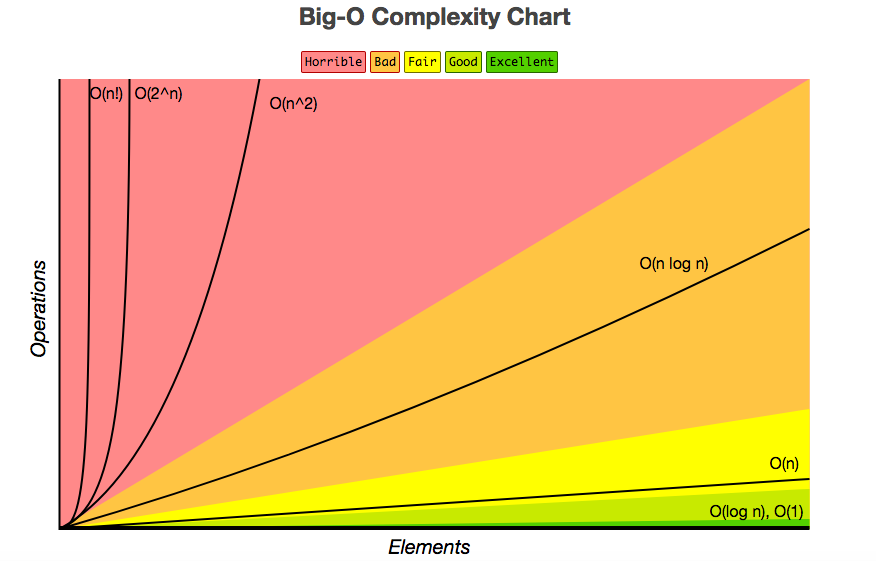
常见的数据结构
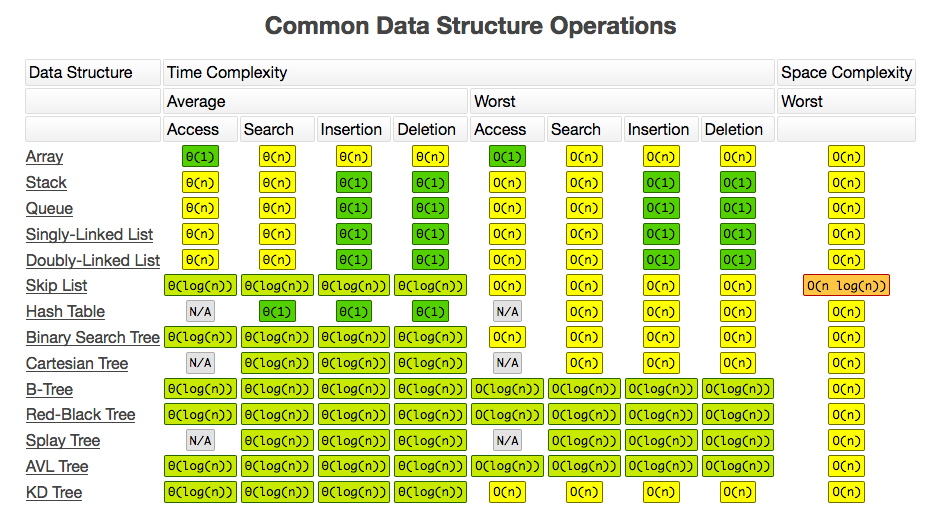
排序算法
常见的排序算法比较:
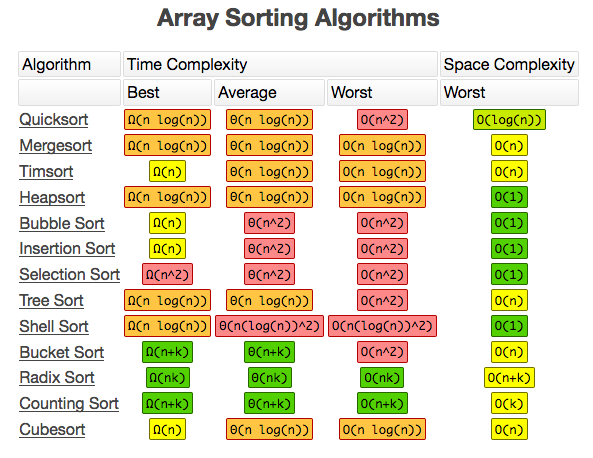
排序算法的稳定性:
排序算法的稳定性通俗地讲,就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。
稳定的排序算法有:基数排序、冒泡排序、直接插入排序、折半插入排序、归并排序。
不稳定的排序算法有:堆排序、快速排序、希尔排序、直接选择排序。
快速排序与归并排序的比较
快速排序的平均情况、最好情况、最坏情况分别是O(n log(n))、O(n log(n))、O(n^2),不稳定。
归并排序的平均情况、最好情况、最坏情况分别是O(n log(n))、O(n log(n))、O(n log(n)),稳定。
简单来说,如果数组是基本数据类型,例如int、double,且数组长度在一定值内(因为数据量太大快速排序的性能不如归并排序),建议使用快速排序,这是因为:
- 排序算法的不稳定性对基本数据类型影响不大
- 快速排序是原地进行的,不需要数组间的复制
而如果数组是复杂数据类型,或者数组长度超过一定值的,建议使用归并排序。
另外,快速排序的最坏情况是O(n^2),这比归并排序的最坏情况要慢得多,这种情况发生在数组已经是有序的,并且在排序时总是将第一个元素用作基准值。但实际上遇上平均情况的可能性比遇上最坏情况要大得多,所以可以认为影响不大。